Vector Embeddings Running Locally: How Browsers Handle Semantic Searches Without External Data Transfers
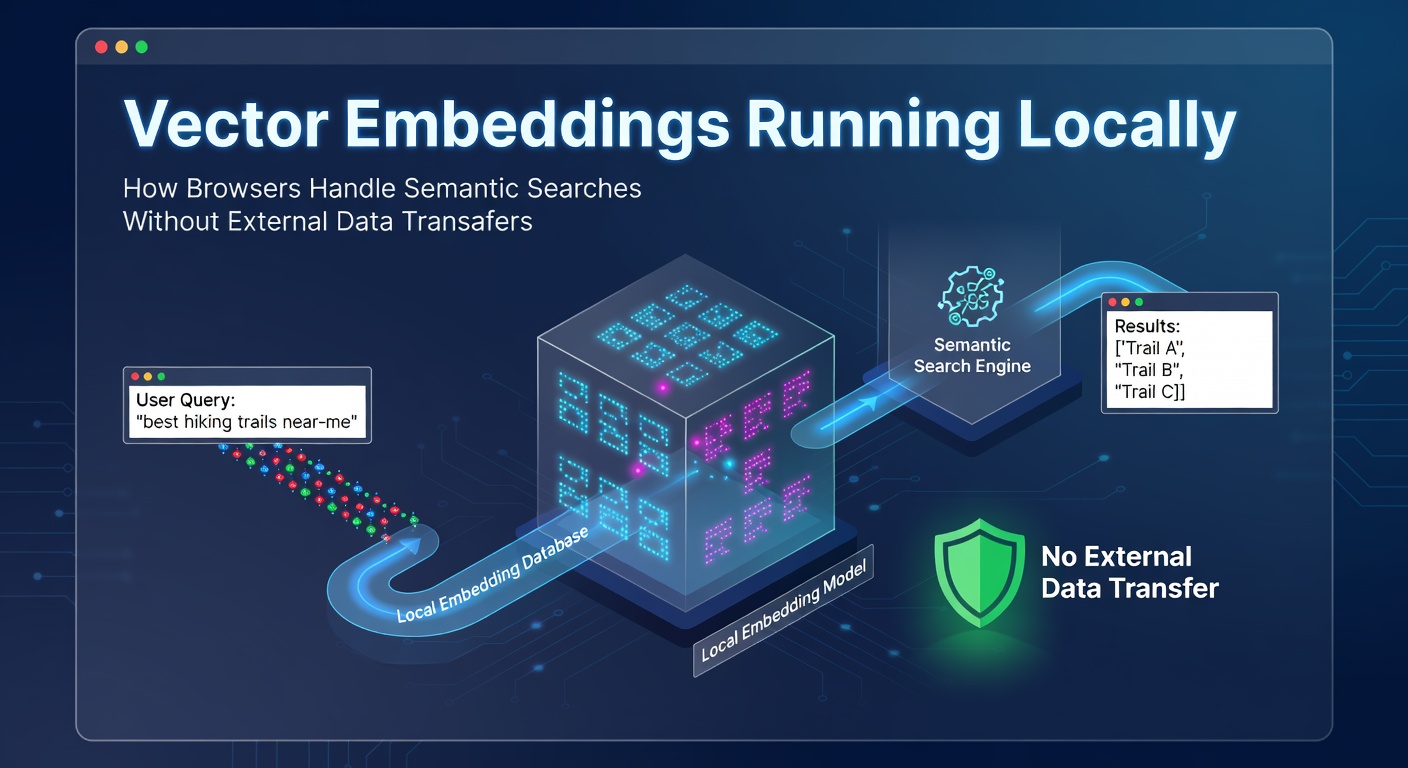
Browsers convert text, images, and other content into vector embeddings through machine learning models that execute directly on the device, enabling semantic searches based on meaning rather than exact keywords while keeping all computations and data within teh local environment. This approach relies on client-side technologies such as WebAssembly modules and optimized JavaScript libraries that load pre-trained embedding models into memory and generate numerical representations without network calls.
Mechanics of Local Vector Generation
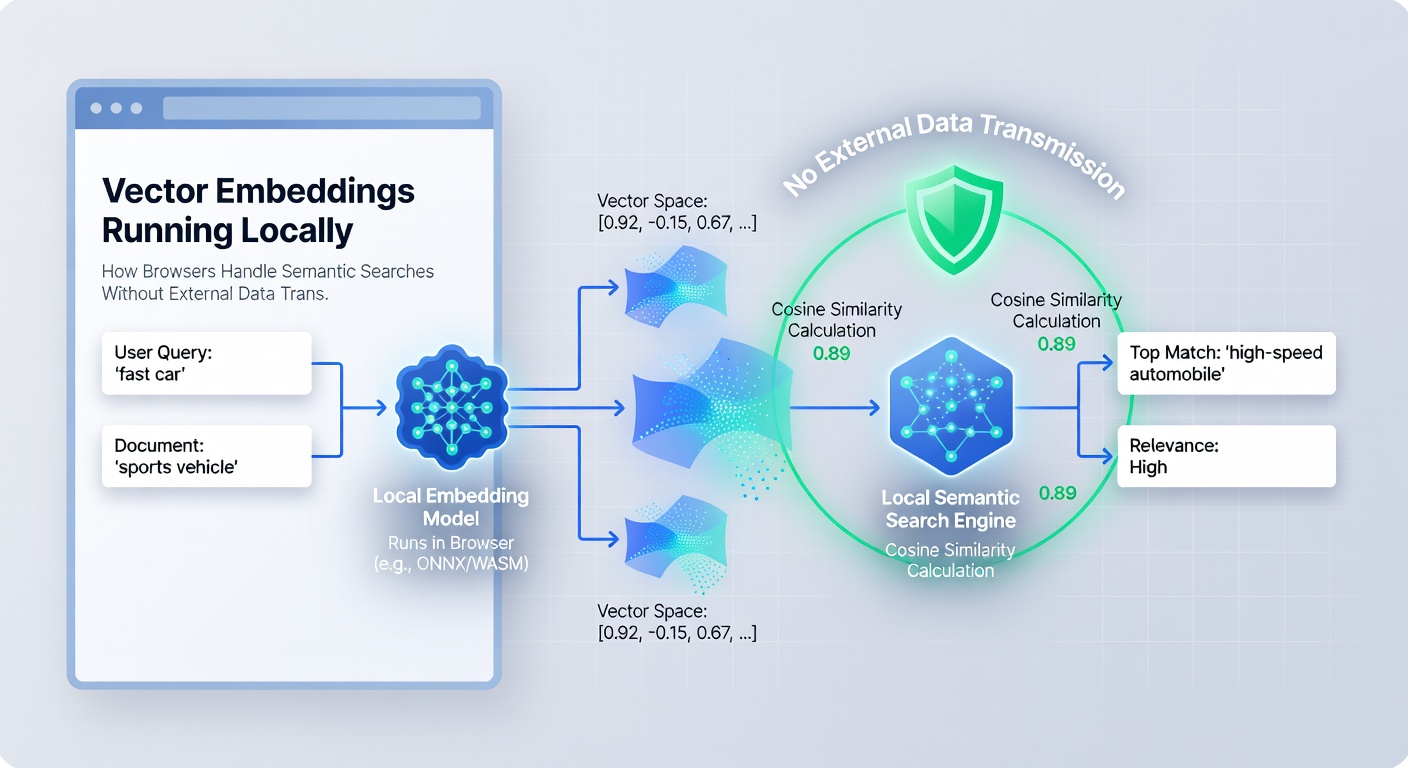
Embedding models transform input data into dense vectors where similar items cluster in mathematical space, and browsers achieve this by running inference pipelines that process user queries or stored documents entirely on the client. Developers integrate these models via formats compatible with browser runtimes, allowing operations like tokenization and matrix multiplications to occur in isolated threads that prevent interference with page rendering. Data stays resident in device memory or IndexedDB storage, which supports persistent local indexes built from user content or downloaded corpora.
Similarity calculations follow vector math principles where cosine distance or dot product metrics rank results according to proximity in embedding space, and this entire workflow completes without transmitting raw inputs or outputs beyond the browser sandbox. Observers note that such architectures support offline functionality because models and indexes persist across sessions, updating only when users explicitly fetch new versions through controlled channels.
Implementation Approaches in Modern Browsers
Current browser engines incorporate support for accelerated computation through APIs that handle tensor operations natively, while libraries compile embedding models into efficient bytecode that executes at near-native speeds. Applications often preload smaller quantized models sized for typical device RAM, balancing accuracy against performance constraints that vary across hardware configurations. Those who have studied deployment patterns report that developers partition indexes into chunks managed by background workers, which query local vector stores and return ranked matches without external dependencies.
Privacy regulations in regions such as the European Union emphasize data minimization, and local embeddings align with these requirements by eliminating transmission of personal content during search operations. In May 2026 browser vendors introduced enhanced storage quotas and improved garbage collection for large vector indexes, allowing sustained performance during extended sessions on mid-range hardware.
Researchers at institutions including the University of Melbourne have documented cases where educational platforms implemented local semantic retrieval for course materials, enabling students to query notes and lecture transcripts without uploading data to institutional servers. These systems build embeddings from user-uploaded files at import time and maintain inverted indexes that support fast approximate nearest-neighbor lookups through algorithms optimized for JavaScript execution environments.
Technical Constraints and Optimizations
Memory limitations on consumer devices require careful model selection, with practitioners often choosing distilled versions of larger embedding networks that retain sufficient semantic fidelity while fitting within typical browser heap sizes. Quantization techniques reduce precision from 32-bit floats to 8-bit integers, cutting storage needs and accelerating inference on CPUs or available GPU resources exposed through web standards. Error rates remain measurable yet acceptable for many retrieval tasks because downstream ranking can incorporate additional filters applied locally.
Security models enforce strict isolation so that embedding computations cannot access cross-origin data or leak vectors through timing side channels, and content security policies further restrict model loading to trusted origins. Updates to model weights occur through signed packages that browsers verify before overwriting local caches, maintaining integrity across distributed user bases.
Current Adoption Patterns
Industry reports from organizations tracking web technology adoption indicate rising integration of local embedding capabilities in note-taking applications, research tools, and personal knowledge bases as of mid-2026. These implementations demonstrate measurable reductions in latency compared with cloud-dependent alternatives because round-trip times disappear entirely once models reside on device. Data from the Australian Cyber Security Centre highlights corresponding decreases in exposure surfaces when organizations shift semantic processing away from centralized repositories.
Interoperability efforts continue through working groups focused on standardized model formats that multiple browser engines can execute without proprietary extensions. This trajectory supports broader deployment across operating systems and device classes while preserving the core guarantee that semantic comparisons remain confined to the client.
Conclusion
Vector embeddings processed locally allow browsers to deliver semantic search functionality through self-contained pipelines that generate, store, and compare representations without external data movement. Continued refinements in model efficiency and runtime support point toward wider availability across consumer applications by the latter half of the decade, grounded in measurable engineering progress and regulatory alignment around data locality.